tags:
- tuto/deepseek
- LLM
- local
- gpt4allInstaller DeepSeek R1 Distill en local
Ce guide s'adresse à un public non spécialisé, qui souhaite s'approprier un grand modèle de langage comme assistant conversationnel de type chatGPT gratuitement sans dépendre des interfaces web comme OpenAI, Google Gemini, Claude et des autres GAFAM par souci de confidentialité des données et émancipation technologique.
Le but est de vous faire prendre en main un logiciel open-source utilisant des modèles open-source gratuits, ici DeepSeek R1 distillé le tout sans aucune compétence technique ni d'ordinateur spécialisé.
Bien évidemment, la puissance de calcul étant un facteur essentiel dans la vitesse d'execution du modèle, la taille du modèle doit être modulée selon les capacités de votre machine.
Plus un modèle est petit, moins il sera performant en qualité de réponse, il ne faut donc pas s'attendre aux capacités de raisonnement des modèles de plusieurs centaines de milliard de paramètres. Cependant, les modèles actuels sont bien assez performants pour beaucoup de tâches banales qui ne nécessitent pas de grande capacité de calcul, en particulier tout ce qui touche au traitement de texte.
On installera ici des modèles de "petite" taille, inférieurs à 8B (8 Billion / Milliard de paramètres), qui peuvent fonctionner correctement sur une machine individuelle.
Prérequis matériel :
Minimal :
Un ordinateur doté d'au moins 8 Go de RAM
Un processeur de moins de 5 ans
~30 Go de libre sur le disque dur
Recommandé :
Une carte graphique (GPU) NVIDIA de moins de 5 ans et 8 Go de VRAM (mémoire dédiée GPU) doté de l'architecture CUDA, ou pour les utilisateurs Apple, une puce M1 ou plus récent.
Etape 0 | Compatibilité GPU Nvidia : installer CUDA Toolkit
Si vous n'avez pas de GPU Nvidia, ignorer cette étape. On peut faire tourner le modèle uniquement sur processeur sans problème.
Sinon,
Installer l'outil CUDA Toolkit pour pouvoir exploiter la GPU avec CUDA en suivant les étapes suivantes :
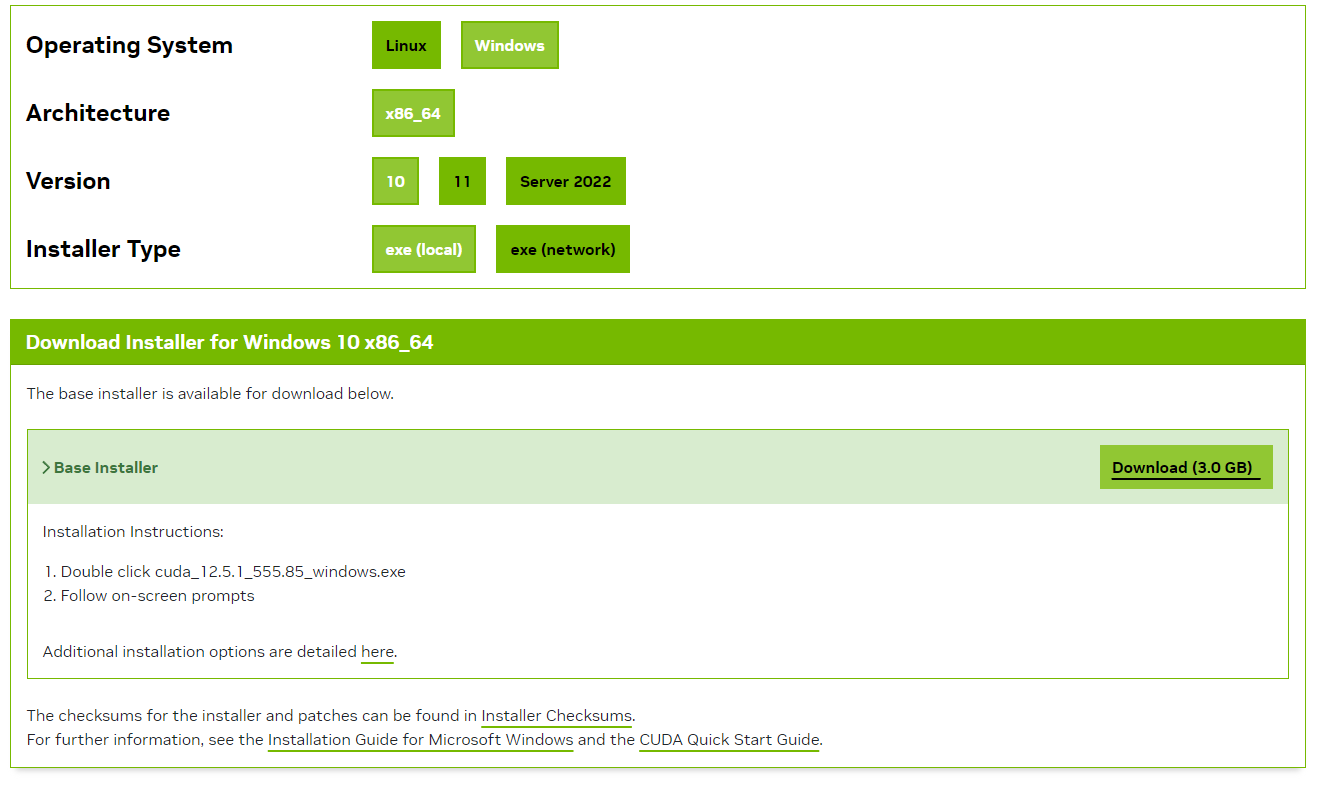
- Suivre les instructions de l'installer .exe après avoir saisi un mot de passe administrateur.
- Cliquer sur suivant jusqu'à cette partie et cocher la case :
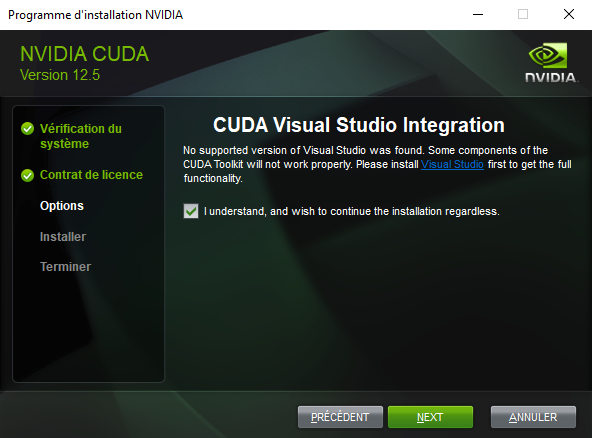
- Suivre les instructions jusqu'à la fin de l'installation.
L'installation de Visual Studio n'est pas nécéssaire pour ce cas d'utilisation.
Voilà, vous pouvez à présent exploiter les capacités de votre carte graphique pour des grands modèles de langage !
Etape 1 : Installer une interface graphique
Il existe plusieurs interfaces dévelopées open-source, comme LM Studio ou Jan (développé dans le tuto Installer une LLM en local pour un humain local)
On se concentrera ici sur l'outil GPT4All, également détaillé dans RAG simple, local et Open-Source avec GPT4All
Aller sur la page : https://www.nomic.ai/gpt4all et télécharger l'installeur adapté à votre système d'exploitation.
Configurer le proxy (si nécéssaire)
Sur le réseau de l'université ou en VPN, il vous sera peut-être nécéssaire de modifier les paramètres de proxy pour pouvoir télécharger des modèles par l'interface graphique.
A ce jour (04/02/25), malgré la configuration du proxy, le téléchargement sur le réseau de l'UJM est toujours bloqué pour moi, il faudra alors télécharger manuellement les modèles sur HuggingFace.
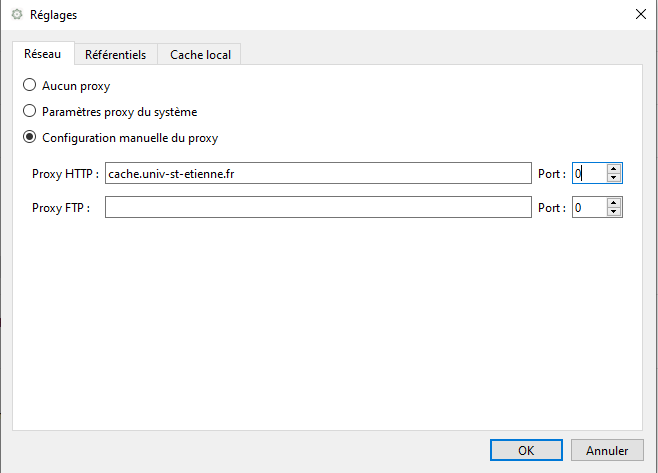
Lors de l'affichage de la première fenêtre, cliquer sur Reglages en bas à gauche :
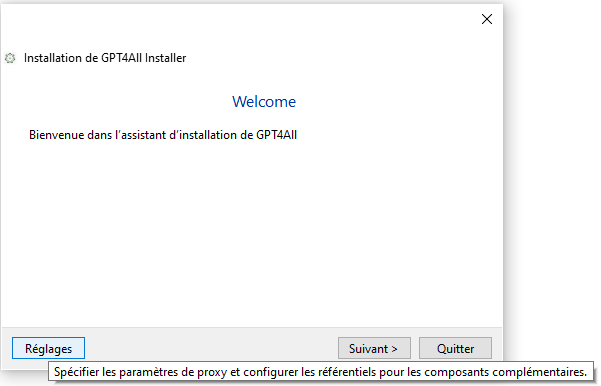
afin de configurer le proxy HTTP : cache.univ-st-etienne.fr
Remplacer le port 0 par le port effectif utilisé dans votre réseau.
Reste de l'installation
Dossier d'installation par défaut dans votre dossier utilisateur :
C:\Users\username\gpt4all , modifier si vous voulez l'installer ailleurs que dans C:\
Suivez les étapes jusqu'à la fin :
Si le proxy est correctement configuré, le téléchargement des données se fait par internet.
Sinon, l'installation peut se faire entièrement en local également.
Fin de l'installation, vous allez pouvoir commencer à utiliser GPT4All ! 🎉
Pour plus de détails sur l'utilisation du logiciel, se référer à la très claire documentation officielle
Télécharger manuellement un modèle depuis HuggingFace
https://huggingface.co/ est une plateforme qui héberge et soutient la communauté open-source d'IA, en particulier les grands modèles de langages.
Vous pouvez, dans la barre de recherche, trouver n'importe quel modèle open-source disponible. Nous allons utiliser ici les versions distillées du modèle DeepSeek R1 de base, qui sont des version compressées du modèle original faisant 671B de paramètres (trop lourd donc pour notre machine normale)
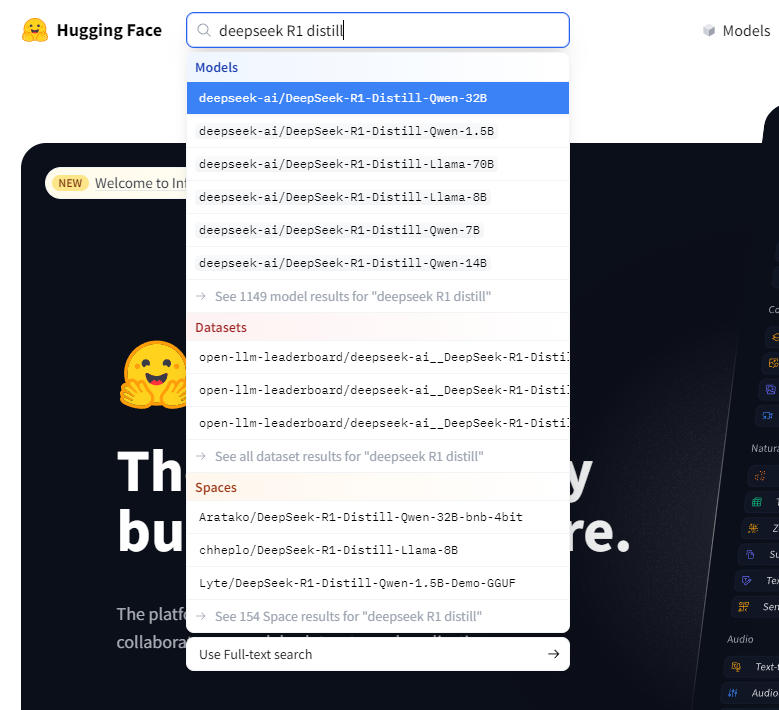
Nous allons ici télécharger le modèle suivant :
bartowski/DeepSeek-R1-Distill-Qwen-7B-GGUF
(Libre à vous d'utiliser d'autres modèles distillés dans la liste précédente adapté à vos besoins)
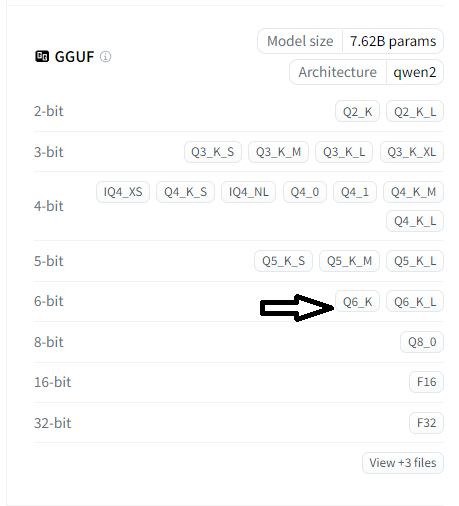
Sur cette page est affichée toutes les informations nécessaires pour choisir un modèle adapté à votre machine, dont un tableau récapitulatif de la taille du fichier du modèle et sa qualité de compression suite à la quantification (réduction des poids des modèles de 32bits à 4 bits par exemple) :
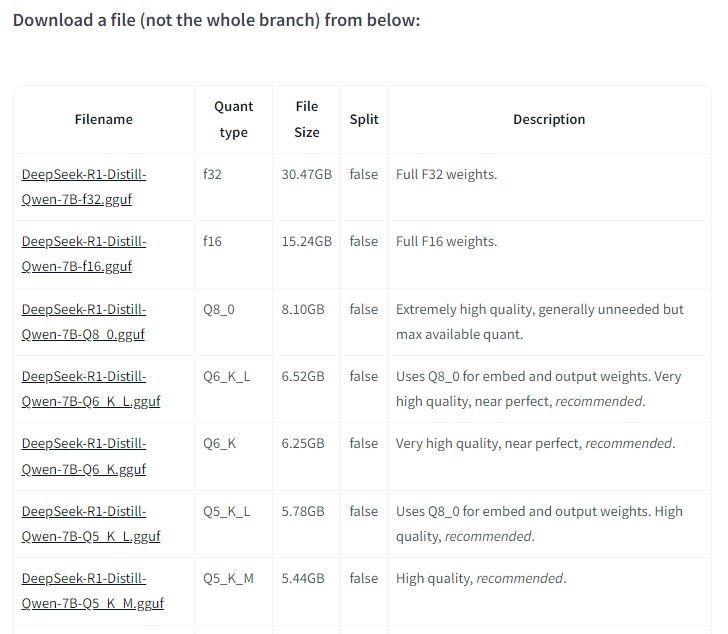
Une bonne estimation de la taille en mémoire de votre modèle sera de 1,2 x Taille en Billion / Milliard (ex: modèle 8B prendra environ 9,6 Go de mémoire )
Les modèles quantifiés sont proposés au format .GGUF qui permettra de l'utiliser directement avec des tailles inférieures.
En l'occurrence, la taille recommandée par défaut est la suivante, qui demandera environ 6 Go de mémoire VRAM :
| Filename | Quant type | File Size | Description |
|---|---|---|---|
| DeepSeek-R1-Distill-Qwen-7B-Q4_K_M.gguf | Q4_K_M | 4.68GB | Good quality, default size for most use cases, recommended. |
En cliquant sur le lien vous arrivez sur la page de téléchargement :
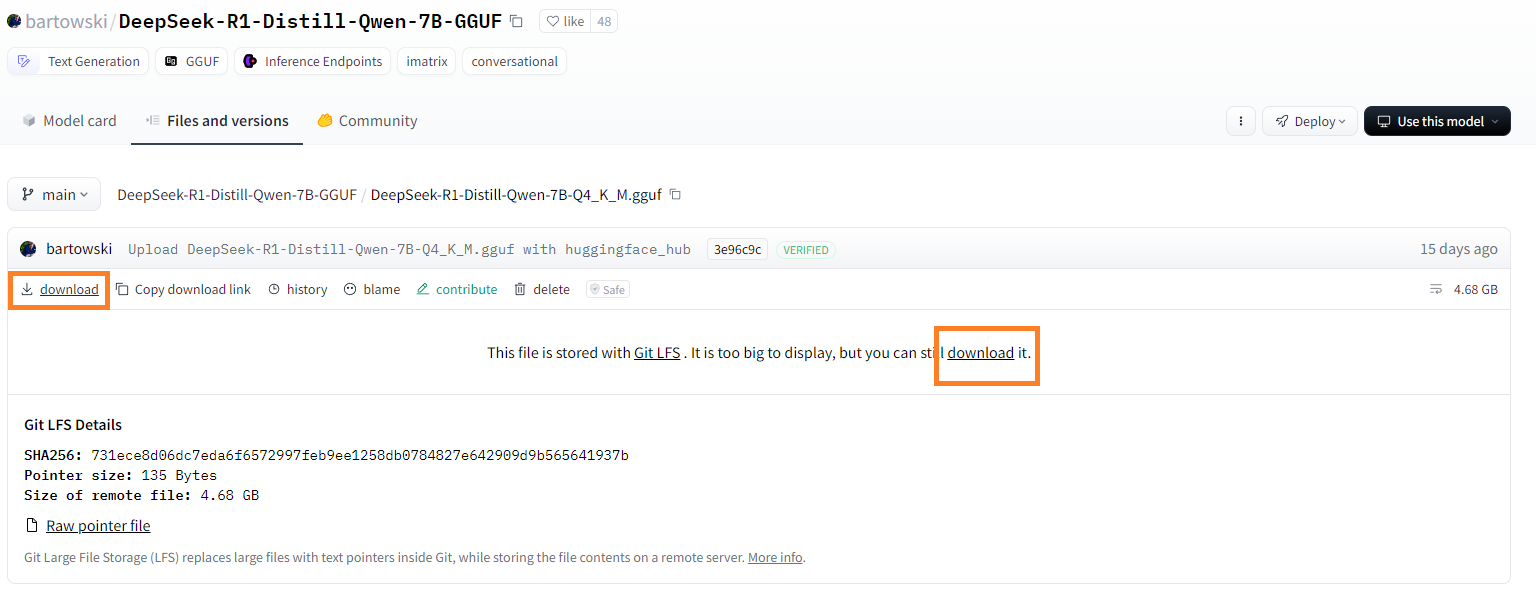
où il vous suffira de cliquer sur un des boutons "download" surlignés.
Bravo !👏 Vous avez fini l'étape de téléchargement d'un modèle open-source.
Il suffit maintenant de déposer le modèle téléchargé dans le dossier de GPT4All accessible par défaut dans :C:/Users/<username>/AppData/Local/nomic.ai/GPT4All/
et configurable dans l'onglet "Settings" de GPT4All :
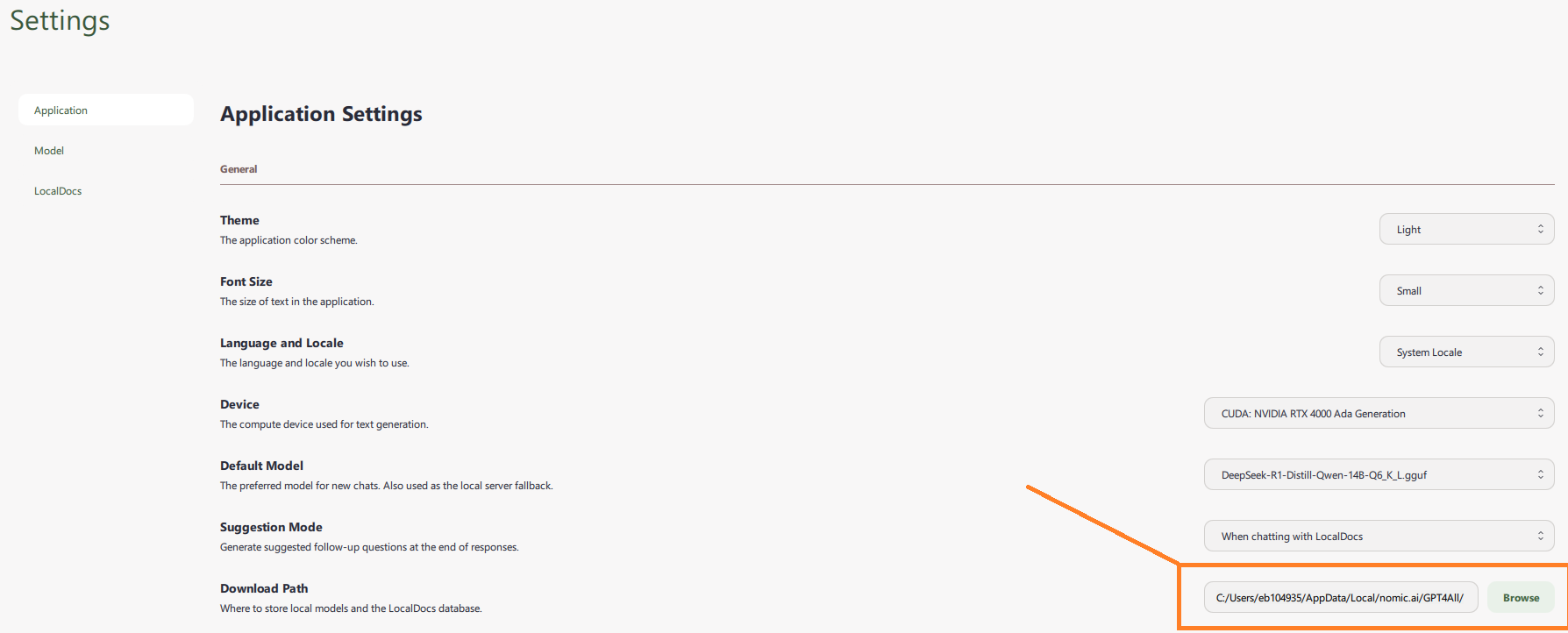
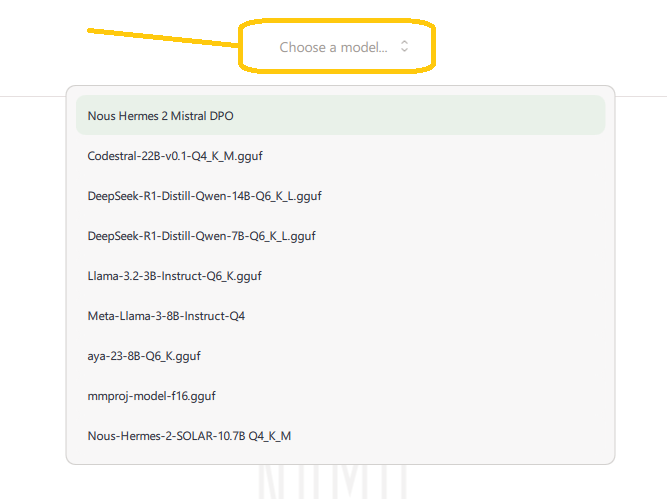
Et puis de relancer l'application pour le voir apparaître dans le menu déroulant de l'onglet chat "Choose a model" :
Configuration fine supplémentaire
Pour que le modèle affiche correctement sa sortie avec l'onglet de chaîne de réflexion "thinking", Aller dans :
Settings > Model > Chat Template :
Supprimer le "system message" prompt pour avoir quelque chose comme ça :
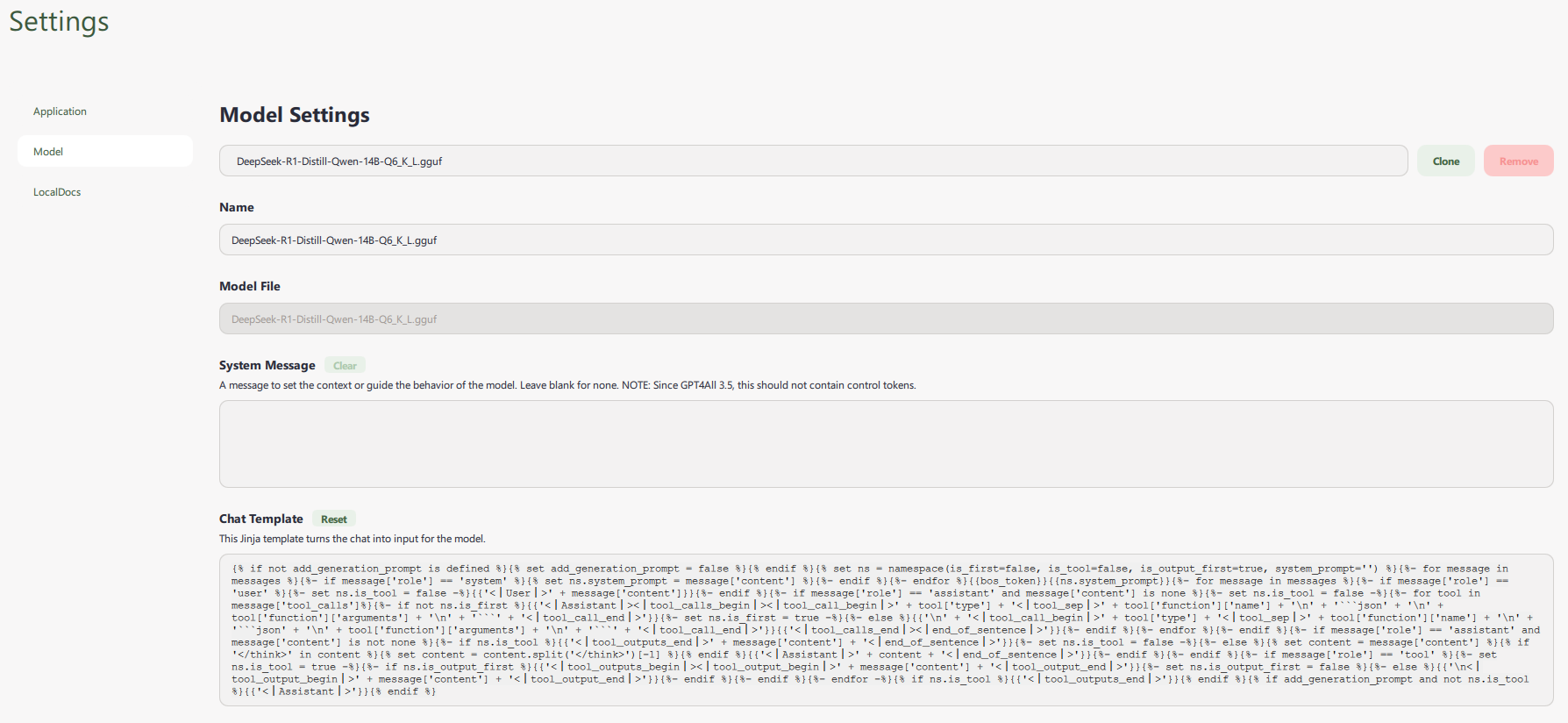
et copier/coller le chat template suivant :
{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% set ns = namespace(is_first=false, is_tool=false, is_output_first=true, system_prompt='') %}{%- for message in messages %}{%- if message['role'] == 'system' %}{% set ns.system_prompt = message['content'] %}{%- endif %}{%- endfor %}{{bos_token}}{{ns.system_prompt}}{%- for message in messages %}{%- if message['role'] == 'user' %}{%- set ns.is_tool = false -%}{{'<|User|>' + message['content']}}{%- endif %}{%- if message['role'] == 'assistant' and message['content'] is none %}{%- set ns.is_tool = false -%}{%- for tool in message['tool_calls']%}{%- if not ns.is_first %}{{'<|Assistant|><|tool▁calls▁begin|><|tool▁call▁begin|>' + tool['type'] + '<|tool▁sep|>' + tool['function']['name'] + '\n' + '```json' + '\n' + tool['function']['arguments'] + '\n' + '```' + '<|tool▁call▁end|>'}}{%- set ns.is_first = true -%}{%- else %}{{'\n' + '<|tool▁call▁begin|>' + tool['type'] + '<|tool▁sep|>' + tool['function']['name'] + '\n' + '```json' + '\n' + tool['function']['arguments'] + '\n' + '```' + '<|tool▁call▁end|>'}}{{'<|tool▁calls▁end|><|end▁of▁sentence|>'}}{%- endif %}{%- endfor %}{%- endif %}{%- if message['role'] == 'assistant' and message['content'] is not none %}{%- if ns.is_tool %}{{'<|tool▁outputs▁end|>' + message['content'] + '<|end▁of▁sentence|>'}}{%- set ns.is_tool = false -%}{%- else %}{% set content = message['content'] %}{% if '</think>' in content %}{% set content = content.split('</think>')[-1] %}{% endif %}{{'<|Assistant|>' + content + '<|end▁of▁sentence|>'}}{%- endif %}{%- endif %}{%- if message['role'] == 'tool' %}{%- set ns.is_tool = true -%}{%- if ns.is_output_first %}{{'<|tool▁outputs▁begin|><|tool▁output▁begin|>' + message['content'] + '<|tool▁output▁end|>'}}{%- set ns.is_output_first = false %}{%- else %}{{'\n<|tool▁output▁begin|>' + message['content'] + '<|tool▁output▁end|>'}}{%- endif %}{%- endif %}{%- endfor -%}{% if ns.is_tool %}{{'<|tool▁outputs▁end|>'}}{% endif %}{% if add_generation_prompt and not ns.is_tool %}{{'<|Assistant|>'}}{% endif %}
Attention, cela peut varier selon les modèles, je vous conseille de plutôt aller chercher à la source, détaillé ici :
PS : Le template de chat original est accessible dans la fiche du modèle précédente sur huggingface en cliquant sur l'un des boutons des versions de modèles :
Dans l'onglet métadata :
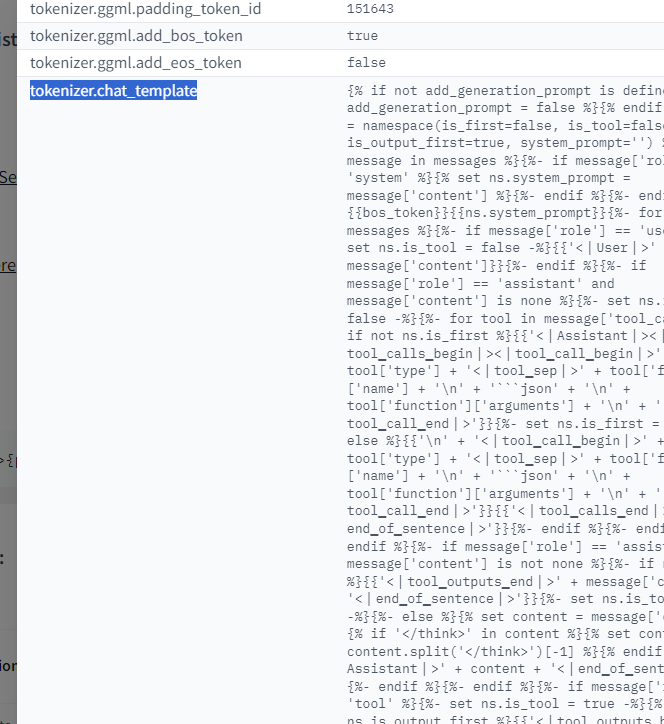
En bas de page des settings, on peut modifier les éléments suivants :
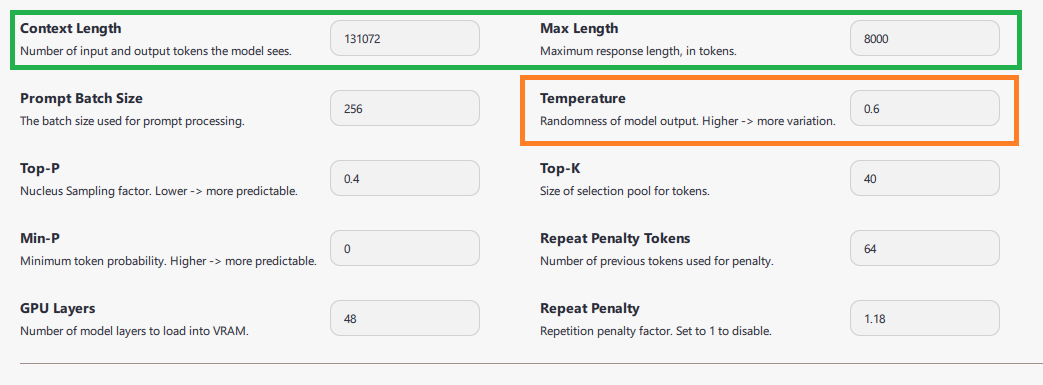
Configurer la taille de contexte maximale selon la mémoire disponible en plus de celle occupée par le modèle. (ici 131k tokens, mais vous pouvez limiter selon la configuration matérielle à 10k tokens par ex.)
La Context Length ou taille de contexte contraint la quantité de texte que le modèle voit à un instant T lors de la génération.
En d'autres termes, c'est une fenêtre glissante de texte qui prend en compte :
les instructions explicitement saisies par l'utilisateur (vous) + les instructions de template de chat + Les discussions précédentes + les étapes de réflexion "Chain-of-Thought Prompting" précédentes .
Max Length Contrôle la quantité max. de tokens générés en sortie, dont les tokens de "réflexion" pour les modèles de réflexion comme DeepSeek R1. Ce paramètre contraint donc à la fois la longueur maximale de la réponse mais également le temps de réflexion du modèle. J'utilise 8k tokens mais vous pouvez essayer avec différentes valeurs.
La Temperature conseillée par les développeurs de DeepSeek est de 0.6
Ce paramètre contrôle la variabilité de la génération.
Laisser les autres paramètres par défaut.
Et voilà, votre modèle DeepSeek R1 Distill est prêt à l'utilisation ! 😎
Vous pouvez le coupler à des documents locaux sur votre machine en toute sécurité et confidentialité en suivant le guide RAG simple, local et Open-Source avec GPT4All.